인식한 상황
초기 데이터베이스 설계에서는 모든 댓글을 하나의 comment 테이블로 관리하는 등 null이 매우 많은 raw를 가진 like, review, report 등이 존재했다. 즉, 다양한 엔티티를 참조하는 여러 개의 외래 키(예: 게시물 ID, 학원 ID 등)가 모두 포함되어 있었다.
이러한 설계로 인해 각 댓글이 실제로 참조하지 않는 컬럼에는 null 값이 많이 발생했다. 또한, 새로운 기능을 넣을 때 Comment 테이블에 Column이 추가되는 상황이 빈번했다. (아…)
기존 DB의 일부분
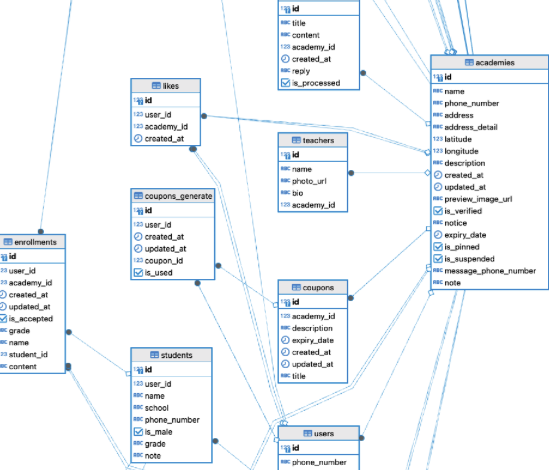
일부분이지만 Academy 테이블에 줄만 봐도 어지럽다… 전체적으로 null 값을 없애고, 따로 table을 구성하는 작업이 필요해 보인다…
해결 과정
Comment 테이블에 null 값이 너무 많은 문제를 생각하여 각 ID를 분리할 수 없을까 생각했다. 생각하다 보니 데이터베이스프로그래밍 강의에서 배운 Super-Sub 관계를 적용하는 것이 어떨까라는 생각을 하였다.
기존 관계를 공통 속성을 가진 상위 comment 테이블을 만들고, 특정 엔티티와 참조하는 하위 테이블을 Super - Sub 관계로 정의했다.
- 상위 테이블: comment (공통 컬럼: id, 작성자, 내용, 생성일 등)
- 하위 테이블: post_comment (추가 컬럼: post_id), academy_comment (추가 컬럼: academy_id)
ORM에서는 InheritanceType.JOINED 전략을 사용하여 상속 관계를 테이블 간의 조인으로 표현했다. 또한, @DiscriminatorColumn과 @DiscriminatorValue를 통해 각 서브 클래스의 유형을 구분하였다.
JPA 예시(Like Table)
@Entity
@Getter
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@Table(name = "likes")
@Inheritance(strategy = InheritanceType.JOINED)
@DiscriminatorColumn(name = "dtype")
public abstract class Like {
/* -------------------------------------------- */
/* -------------- Default Column -------------- */
/* -------------------------------------------- */
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "id")
private Long id;
// ...
}
@Entity
@Getter
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@Table(name = "comment_likes")
@DiscriminatorValue("COMMENT")
public class CommentLike extends Like {
// ...
/* -------------------------------------------- */
/* ----------------- Functions ---------------- */
/* -------------------------------------------- */
@Builder
public CommentLike(
User user,
Comment comment
) {
super(user);
// Relation Column
this.comment = comment;
}
}
변경된 Table 일부분

결과
확장 가능한 설계를 제공하여 비즈니스 확장 시 개발 리소스를 절약할 수 있으며, 기존 코드를 크게 변경하지 않고도 개발이 가능하도록 재구성할 수 있었다. 또한, 데이터베이스 최적화 측면에서 중복 데이터를 제거하고 참조 무결성을 강화하여 데이터베이스의 성능과 안정성을 향상했으며 시스템의 효율성을 높이고 유지보수 비용을 감소시킬 수 있었다.
하지만 InheritanceType.JOINED 를 사용하며 상속된 데이터를 조회할 때, 여러 테이블 간의 조인으로 인해 쿼리 성능이 저하될 수 있었다. 만약 반정규화를 하면 합칠 수 있겠지만, 확장성과 유지보수에 더 높은 가중치를 두었기에 JOINED 전략을 선택하게 되었다.