인식한 상황
MVP 1단계에서 최소한의 기능을 개발하고 사용자가 질문을 생성할 때, 기존에는 다음과 같은 흐름으로 진행했다.
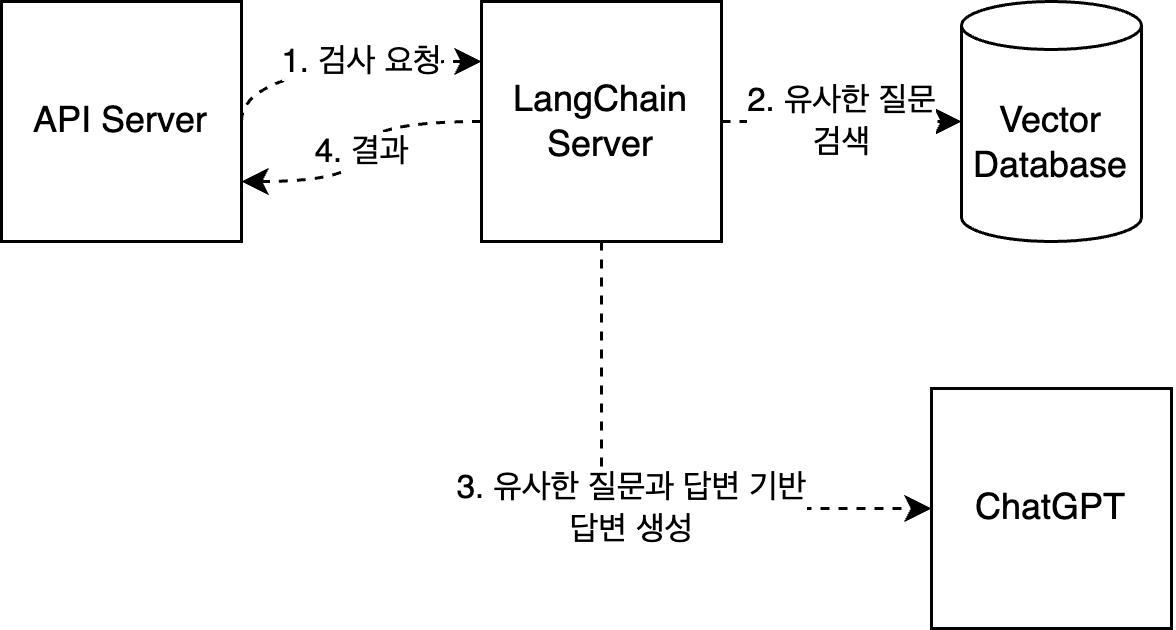
질문을 생성하면 기존 질문과의 유사도를 검사한다.
유사한 질문이 있으면 GPT를 통해 유사한 답변을 생성 후, 질문과 답변을 모두 저장한 뒤 응답한다.
유사한 질문이 없으면 질문만 저장하고 응답한다.
이러한 구조는 질문 생성 시 유사한 질문이 없을 때, API 대기 시간이 길어지는 문제가 있었다. 또한, 사용자에게 질문을 생성하는 동안 다른 기능을 사용하기 어렵다는 피드백을 받았다.
해결 과정
스켈레톤 및 애니메이션 로딩 효과로 UX를 높였다고 생각했지만 길면 5s, 빠르면 100ms 이하로 편차가 매우 큰 API라서 그런지 사용자들이 싫어하는 모습이 너무 눈에 보였다. 또한, 질문은 자주 하게 되므로 더 크게 느껴진 거 같다. 기존 로직은 다음 사진과 같다.
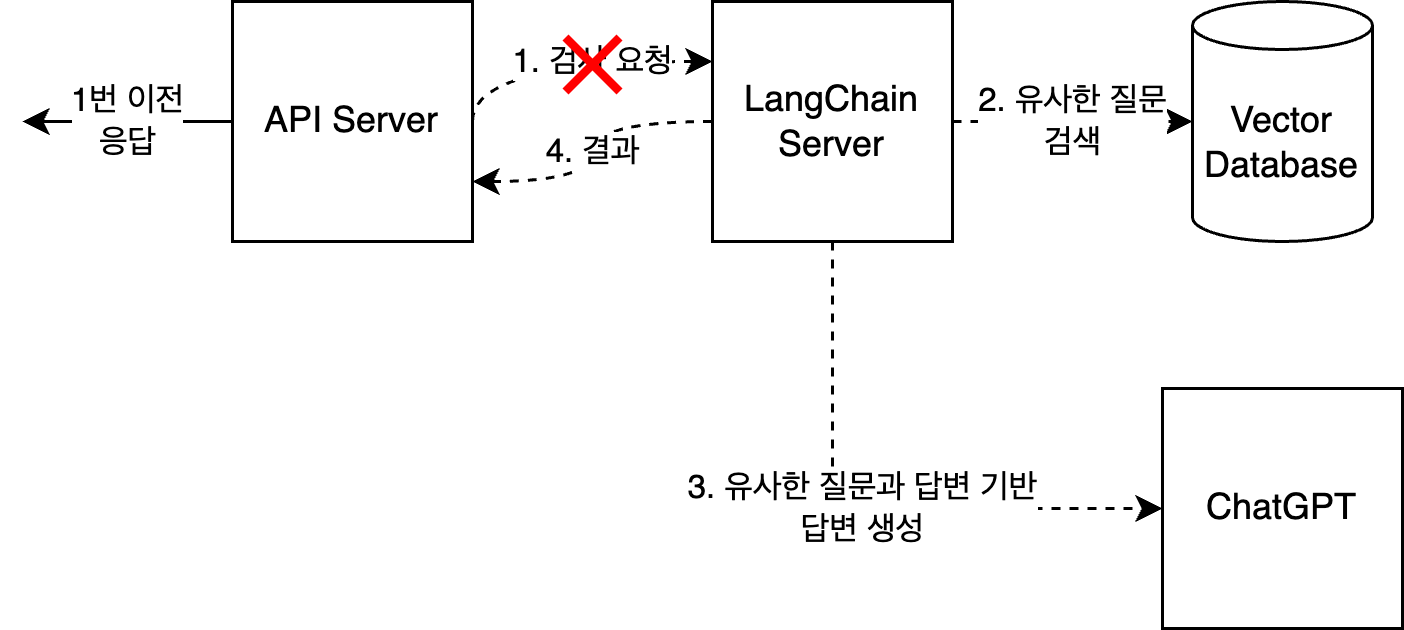
첫 번째 시도: 이벤트 기반 비동기 처리 도입
질문을 DB에 대기 상태로 저장하고 Event를 발생시킨 뒤 사용자에게 200을 반환하도록 했다. 이때, @Async Annotation을 이용하여 검사와 답변 생성을 비동기로 진행하도록 했다.
이후 크롤링을 통해 수집한 질문 10만 개로 대해서 AWS의 Lambda로 사용하여 부하 테스트를 진행했다. 하지만 Django로 이루어진 Langchain Server에서 Too Many Request가 발생했다…!!
두 번째 시도: 대기열 도입
처리를 고려하지 않고 보내다 보니 대기열이 필요하다고 생각되어 Http 요청을 사용하던 로직에서 Kafka를 이용하는 로직으로 변경하고 도입하고 아래와 같이 변경했다.
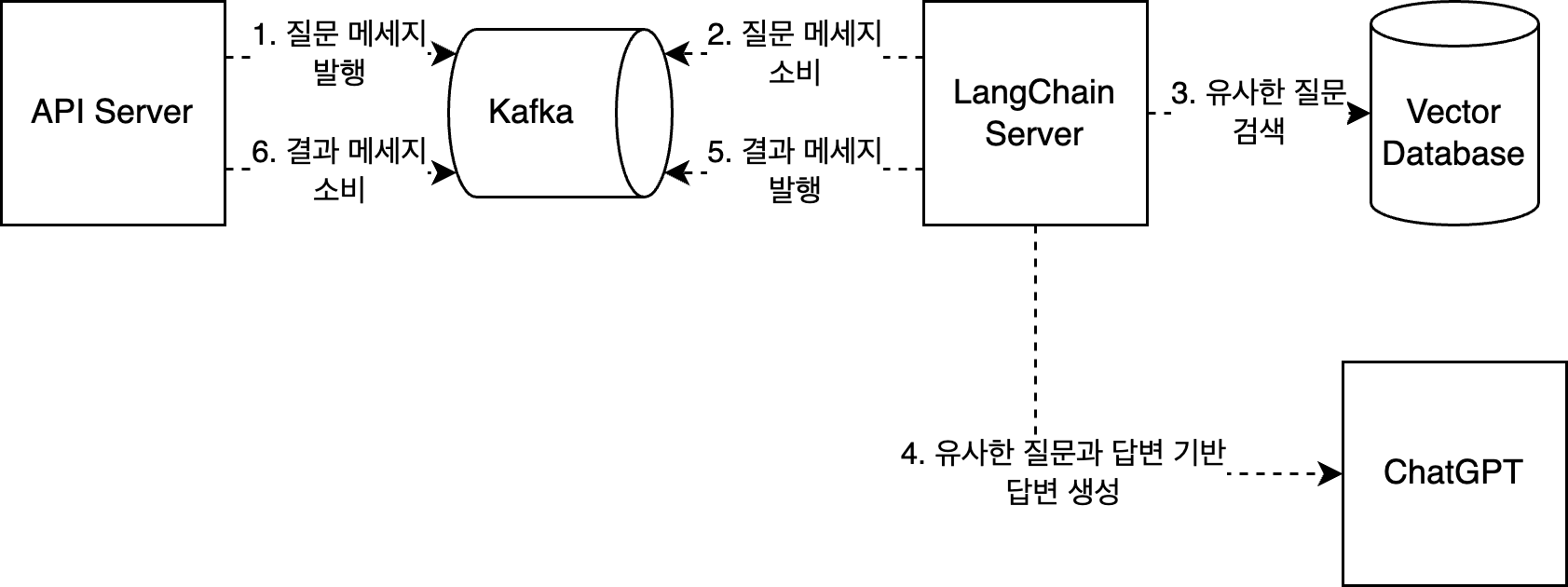
변경 이후 부하 테스트에서 Kafka Message 소비 속도가 느렸지만, 이는 LangChain 서버를 스케일 아웃함으로서 해결할 수 있겠다고 생각했다.
개발 환경에서의 Kafka 설정 이슈 해결
Docker Container 환경에서 Kafka를 사용할 때, replication factor를 1로 설정했음에도 3으로 동작하는 문제가 발생하였다. Kafka 공식 문서와 Docker Image 문서를 검토한 결과, Default Replication Factor와 Offsets Topic Replication Factor 설정이 서로 다른 것이 문제임을 파악했다.
이 둘을 모두 1로 설정하고 Container를 재구성한 결과, 원하는 대로 복제 수를 1로 통일할 수 있었다. 이를 통해 개발 환경에서 Kafka를 안정적으로 운영할 수 있었고, 메시지 처리 로직을 의도한 대로 동작시키는 데 성공했다(실제 테스팅 환경은 복제 수를 3으로 했다).
결과
로직 개편을 통해 질문 생성 시 사용자 대기 시간을 획기적으로 줄였다. 기존에 평균 2~3s 걸리던 응답 시간이 평균 100ms로 단축되어 사용자 경험을 크게 개선하였다.
다만 아쉬운 점이 있다면 유사한 질문이 없지만, 2개의 질문이 같은 경우가 생각났다. 현재 로직에서는 1번과 2번 질문이 유사하더라도 답변이 달린 다른 유사한 질문이 없다면 강의자가 질문에 대해 답변을 해야 한다. 만약 1번 질문에 대한 답변이 생기더라도 2번 질문의 유사한 답변이 자동으로 생성되지 않아서 아쉬운 점이 있다.
추후 개선점으로 남겨두고 조금 더 고민해볼 수 있는 기회를 얻은 거 같다. 이런 시스템 아키텍처를 만져본 적 없는 나로서는 새로운 관점을 얻은 거 같다.